Businesses today increasingly depend on the ability to process and analyze large volumes of information for effective decision-making. ETL pipelines, which stand for Extract, Transform, Load, are essential tools for handling such tasks. These pipelines move data from various sources, process it into a structured format, and store it in a target database, such as PostgreSQL.
A PostgreSQL ETL is increasingly popular due to its flexibility, robustness, and support for complex operations. This tutorial provides a step-by-step guide to building an ETL pipeline with PostgreSQL, emphasizing its components and best practices to ensure efficiency and reliability.
What is ETL Pipelines and its Components
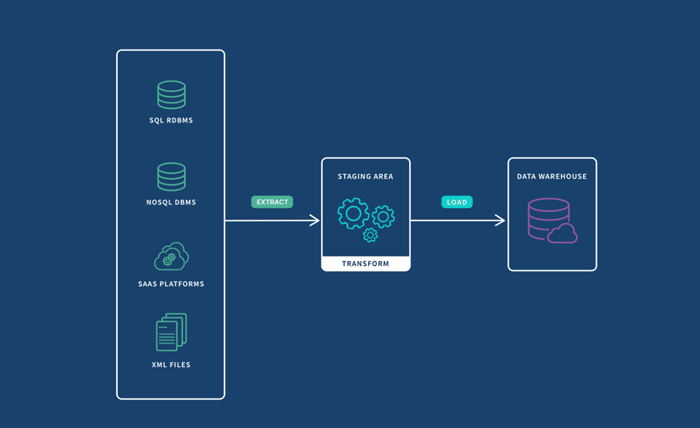
An ETL pipeline is a systematic workflow designed to extract raw information from various sources, transform it into a usable format, and load it into a destination like PostgreSQL. These pipelines simplify data management, enabling organizations to consolidate information for seamless analysis and reporting.
The three components of an ETL pipeline are as follows:
- Extract: This involves gathering data from different sources, which may include databases, APIs, or files. It often comes in diverse formats and structures, necessitating a flexible extraction process.
- Transform: After extraction, the raw data undergoes processing to prepare it for the target database. Transformations may include cleaning, filtering, aggregating, or converting data to meet specific requirements.
- Load: In the final step, the transformed data is saved into a storage system, where it can be queried and analyzed efficiently.
ETL pipelines play a crucial role in enabling businesses to integrate disparate sources into a centralized system, with PostgreSQL being a popular choice for its scalability and advanced query capabilities.
Step-by-Step Guide to Building an ETL Pipeline with PostgreSQL
Building an ETL pipeline involves a series of systematic steps. Below is an exploration of each phase of the process in detail.
Step 1: Define Data Sources
The first step in building an ETL pipeline is identifying and defining the data sources from which you need to collect information. These sources may include relational databases, external APIs, spreadsheets, or other storage systems. Understanding the structure and type of data—whether structured, semi-structured, or unstructured—is critical at this stage.
For example, a company might gather sales data from its internal systems, customer information from a CRM platform, and additional market information from third-party APIs. Properly defining these sources ensures that the extraction phase will align with the pipeline’s overall objectives, especially when considering Informatica alternatives open-source for different data integration needs.
Step 2: Extract Data
The extraction phase involves retrieving raw data from the defined sources. Depending on the source, the extraction process may vary. For instance, data from a database can be fetched using SQL queries, while information from an API requires making specific calls to retrieve the required information.
This phase often involves storing the extracted data temporarily in a staging area or in memory, allowing it to be prepared for the next step. Care must be taken to handle connectivity issues, large volumes, and varying formats during this phase. It also requires careful monitoring to ensure the accuracy and completeness of the extracted data before moving on to further processing steps.
Step 3: Data Transformation
Once the raw data has been extracted, it is processed to meet the requirements of the target database. The transformation phase includes tasks such as cleaning up inconsistent values, standardizing formats, filtering irrelevant data, and aggregating information for analysis.
For example, if dates are represented in different formats across sources, they need to be standardized. Similarly, missing or erroneous values must be handled appropriately to ensure the accuracy of the transformed dataset.
This phase is highly customizable, depending on the specific needs of the business. Transformation processes can include creating new calculated metrics, merging datasets, or filtering rows based on certain conditions. The goal is to ensure the data is clean, consistent, and ready for loading into PostgreSQL.
Step 4: Load Data into PostgreSQL
In the final step, the transformed data is moved into the PostgreSQL database. This is where the data becomes accessible for further querying, reporting, and analysis. PostgreSQL offers several methods for loading data efficiently, including batch inserts and bulk operations.
The loading process often involves creating or updating tables within PostgreSQL to accommodate the incoming data. It’s essential to ensure that the data structure aligns with the database schema to avoid errors during this phase. Building an etl pipeline using PostgreSQL allows for efficient data storage and seamless integration with analytical tools. Once the information is successfully loaded, it is ready for use in analytical applications or reporting tools.
Best Practices for ETL with PostgreSQL
When implementing ETL pipelines with PostgreSQL, adhering to best practices ensures that the process is efficient, scalable, and reliable. Here are some key practices to consider:
- Optimize Query Performance: During extraction and loading, optimize SQL queries to minimize execution time. This includes using indexes, avoiding unnecessary joins, and ensuring that the queries are as efficient as possible.
- Monitor and Analyze Performance: PostgreSQL provides tools like EXPLAIN to analyze query execution plans. Regular monitoring helps identify bottlenecks and optimize operations.
- Leverage PostgreSQL Features: Take advantage of PostgreSQL’s built-in features, such as support for JSON data, materialized views, and partitioning. These can simplify data management and improve performance.
- Ensure Data Integrity: Use transactions during the loading phase to maintain atomicity. This ensures that in case of an error, the database remains in a consistent state.
- Automate ETL Processes: Automating the pipeline using tools like Apache Airflow or Cron ensures regular updates and reduces manual intervention. Automation is especially useful for pipelines that need to process data frequently. Referring to a PostgreSQL ETL tutorial during setup can help streamline the automation process and provide guidance for best practices.
- Implement Robust Error Handling: Design the pipeline to gracefully handle issues such as missing data, connectivity errors, or schema changes. Logging and alert mechanisms can help identify and resolve errors quickly.
Conclusion
Building a PostgreSQL ETL pipeline is a systematic process that enables businesses to extract valuable insights from their data. By defining data sources, extracting and transforming raw data, and loading it into PostgreSQL, you can create a pipeline that meets your organization’s data processing needs. It stands out as a reliable choice for ETL pipelines due to its flexibility, scalability, and powerful querying capabilities.



